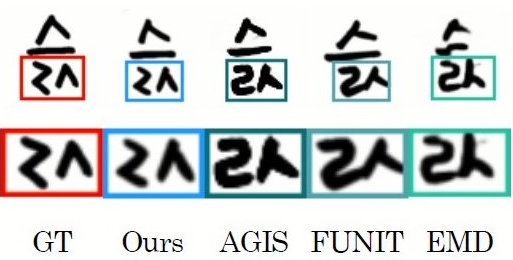
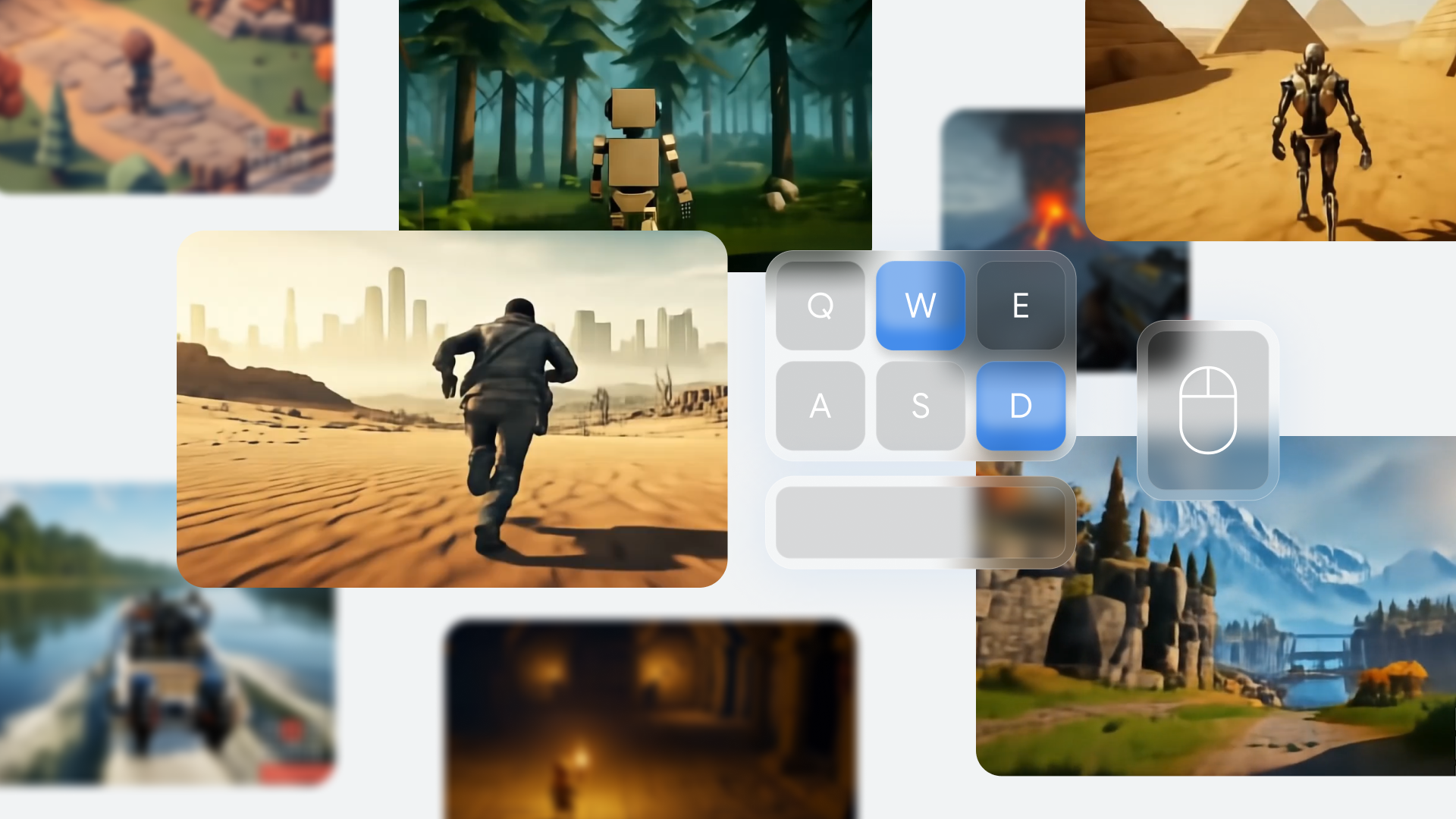
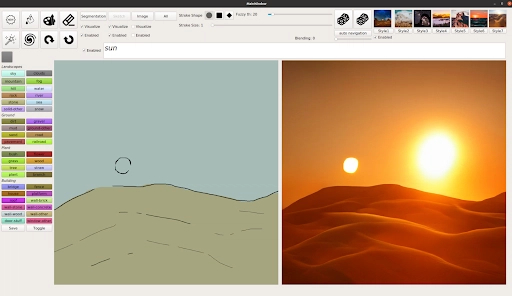
Summary
Content creation plays a crucial role in domains such as photography, videography, virtual reality, gaming, art, design, fashion, and advertising design. Recent progress in machine learning and AI has transformed hours of manual, painstaking content creation work into minutes or seconds of automated or interactive work. For instance, generative modeling approaches can produce photorealistic images of 2D and 3D items such as humans, landscapes, interior scenes, virtual environments, clothing, or even industrial designs. New large text, image, and video models that share latent spaces let us imaginatively describe scenes and have them realized automatically—with new multi-modal approaches able to generate consistent video and audio across long timeframes. Such approaches can also super-resolve and super-slomo videos, interpolate and extrapolate with novel views, decompose scene objects and appearance, and transfer styles to convincingly render and reinterpret content. Learned priors of images, videos, and 3D data can also be combined with explicit appearance and geometric constraints, perceptual understanding, or even functional and semantic constraints of objects. While often creating awe-inspiring artistic images, such techniques offer unique opportunities for generating diverse synthetic training data for downstream computer vision tasks, both in 2D, video, and 3D domains.
The AI for Content Creation workshop explores this exciting and fast-moving research area. We bring together invited speakers of world-class expertise in content creation, up-and-coming researchers, and authors of submitted workshop papers, to engage in a day filled with learning, discussion, and network building.
Welcome! -
James Tompkin (Brown University)

Krishna Kumar Singh (Adobe)
Jun-Yan Zhu (Carnegie Mellon University)
Yuheng Li (Adobe)

Deqing Sun (Google)
Lingjie Liu (University of Pennsylvania)
Lu Jiang (ByteDance)
Yiqing Liang (Luma AI)
Thao Nguyen (UW-Madison)
Author and Submission Instructions
We call for papers (8 pages not including references) and extended abstracts (4 pages not including references) to be presented at the AI for Content Creation Workshop at CVPR.
Papers and extended abstracts will be peer reviewed in a double blind fashion.
Authors of accepted papers will be asked to post their submissions on arXiv.
These papers will not be included in the proceedings of CVPR. Authors should be aware that computer vision conferences consider peer-reviewed works with >4-pages to be in violation of double submission policies, e.g., both
CVPR and
ECCV. We welcome both novel works and works in progress that have not been published elsewhere.
In the interests of fostering a free exchange of ideas, we will also accept for poster presentation a selection of papers that have been recently published elsewhere, including at CVPR 2026; these will not be peer reviewed again, and are not bound to the same anonymity and page limits. A jury of organizers will select these papers.
Paper submissions for 4- and 8-page novel work are double blind and in the CVPR template. You are welcome to include appendices in the main PDF, and upload supplemental material such as videos. There are no dual submissions—please do not submit work for peer review to two workshops simultaneously, nor submit work that is currently in review at another conference (like ICCV/ECCV).
Paper submitters are expected to be reviewers.
📃 Paper (8-page, non-archival) + 📝 Extended Abstract (4-page, non-archival)
Call for Papers: 23rd February 2026 (Anywhere on Earth)
Submission deadline: 23rd March 2026 (Anywhere on Earth)
Acceptance notification: 23rd April 2026 (Anywhere on Earth)
Camera-ready deadline: 30th April 2026 (Anywhere on Earth)
Submission Website: CMT3 - https://cmt3.research.microsoft.com/AICC2026/
The best student papers will be acknowledged with a prize 🏆.
Travel awards (2026): Google Form
Topics
We seek contributions across content creation, including but not limited to techniques for content creation:
- Generative models for image/video/3D synthesis/worlds
- Image/video/3D editing of any kind - inpainting/extrapolation/style
- Domain transfer, e.g., image-to-image or video-to-video techniques
- Multi-modal with text, audio, motion, e.g., text-to-image creation
We also seek contributions in domains and applications for content creation:
- Image and video synthesis for enthusiast, VFX, architecture, advertisements, art, ...
- 2D/3D graphic design
- Text and typefaces
- Design for documents, Web
- Fashion, garments, and outfits
- Novel applications and datasets